This example is taken from the ProBound web server, and corresponds to Figure 6 in the original Nature Biotech publication.
This example produces a model of the sequence-specificity of the tyrosine kinase c-Src by training on data from a Kinase-seq experiment, in which a bacterial display peptide library is exposed to c-Src and anti-phosphotyrosine pulldowns are performed at varying timepoints, which are modeled jointly.
This example uses the Adam optimizer with early stopping. Each minibatch is formed by binning sequences by their level of enrichment and sampling from each bin separately to ensure both strong and weak binders are represented in each optimization step.
import torch
import scipy.stats
import matplotlib.pyplot as plt
import pyprobound
import pyprobound.plotting
import pyprobound.fitting
Data specification
alphabet = pyprobound.alphabets.Protein()
url = "http://pbdemo.x3dna.org/files/example_data/Kinase/"
dataframe = pyprobound.get_dataframe(
[
f"{url}countTable.0.200205_Src-Kinase_5m.tsv.gz",
f"{url}countTable.1.200205_Src-Kinase_20m.tsv.gz",
f"{url}countTable.2.200205_Src-Kinase_60m.tsv.gz",
]
).iloc[:, [0, 1, 3, 5]]
dataframe.head()
# Create validation split for early stopping
val_dataframe, train_dataframe = pyprobound.sample_dataframe(
dataframe, frac=0.3, random_state=0
)
len(train_dataframe), len(val_dataframe)
(160403, 68744)
# Sort for EvenSampler
for df in (val_dataframe, train_dataframe):
df["Enrichment"] = (df.iloc[:, -1] + 1) / (df.iloc[:, 0] + 1)
df.sort_values("Enrichment", inplace=True)
df.drop(columns="Enrichment", inplace=True)
train_count_table = pyprobound.CountTable(
train_dataframe,
alphabet,
left_flank="TAGTSVAGQSGQ",
right_flank="GGQSGQSGDYNK",
left_flank_length=5,
right_flank_length=5,
min_variable_length=min(dataframe.index.str.len()),
max_variable_length=max(dataframe.index.str.len()),
)
val_count_table = pyprobound.CountTable(
val_dataframe,
alphabet,
left_flank="TAGTSVAGQSGQ",
right_flank="GGQSGQSGDYNK",
left_flank_length=5,
right_flank_length=5,
min_variable_length=min(dataframe.index.str.len()),
max_variable_length=max(dataframe.index.str.len()),
)
Model specification
PSAMs
nonspecific = pyprobound.layers.NonSpecific(alphabet=alphabet, name="NS")
psam = pyprobound.layers.PSAM(
kernel_size=7,
alphabet=alphabet,
pairwise_distance=6,
seed=["***Y***"],
seed_scale=45,
name="Src",
)
Modes
modes = [
pyprobound.Mode.from_nonspecific(nonspecific, train_count_table),
pyprobound.Mode.from_psam(psam, train_count_table),
]
Rounds
round_0 = pyprobound.rounds.InitialRound()
round_1 = pyprobound.rounds.ExponentialRound.from_binding(
modes,
round_0,
delta=-15,
train_delta=True,
target_concentration=0.25,
train_concentration=True,
name="5m",
)
round_2 = pyprobound.rounds.ExponentialRound.from_round(
round_1, round_0, target_concentration=1.0, name="20m"
)
round_3 = pyprobound.rounds.ExponentialRound.from_round(
round_1, round_0, target_concentration=3.0, name="60m"
)
# Set log contributions to be 0 instead of -inf
for ctrb in round_1.aggregate.contributions:
ctrb.set_contribution()
Experiments
experiment = pyprobound.Experiment(
[round_0, round_1, round_2, round_3],
name="Src",
counts_per_round=train_count_table.counts_per_round,
)
Model
model = pyprobound.MultiExperimentLoss([experiment], pseudocount=0)
Fitting
optimizer = pyprobound.Optimizer(
model,
[train_count_table],
[val_count_table],
batch_size=2048,
greedy_threshold=2e-4,
device="cpu",
checkpoint="Src_earlystop.pt",
output="Src_earlystop.txt",
sampler=pyprobound.EvenSampler,
optimizer=torch.optim.Adam,
)
optimizer.train_simultaneous()
tensor(1.0766)
optimizer.reload()
{'time': 'Tue Apr 23 19:14:47 2024',
'version': '1.3.1',
'flank_lengths': ((5, 5),)}
Loss
with torch.inference_mode():
train_loss, train_reg = model([train_count_table])
print(
f"Train:\tLoss={train_loss:.3f}, Reg={train_reg:.3f}, Sum={train_loss+train_reg:.3f}"
)
val_loss, val_reg = model([val_count_table])
print(
f"Val:\tLoss={val_loss:.3f}, Reg={val_reg:.3f}, Sum={val_loss+val_reg:.3f}"
)
Train: Loss=1.057, Reg=0.001, Sum=1.058
Val: Loss=1.076, Reg=0.001, Sum=1.077
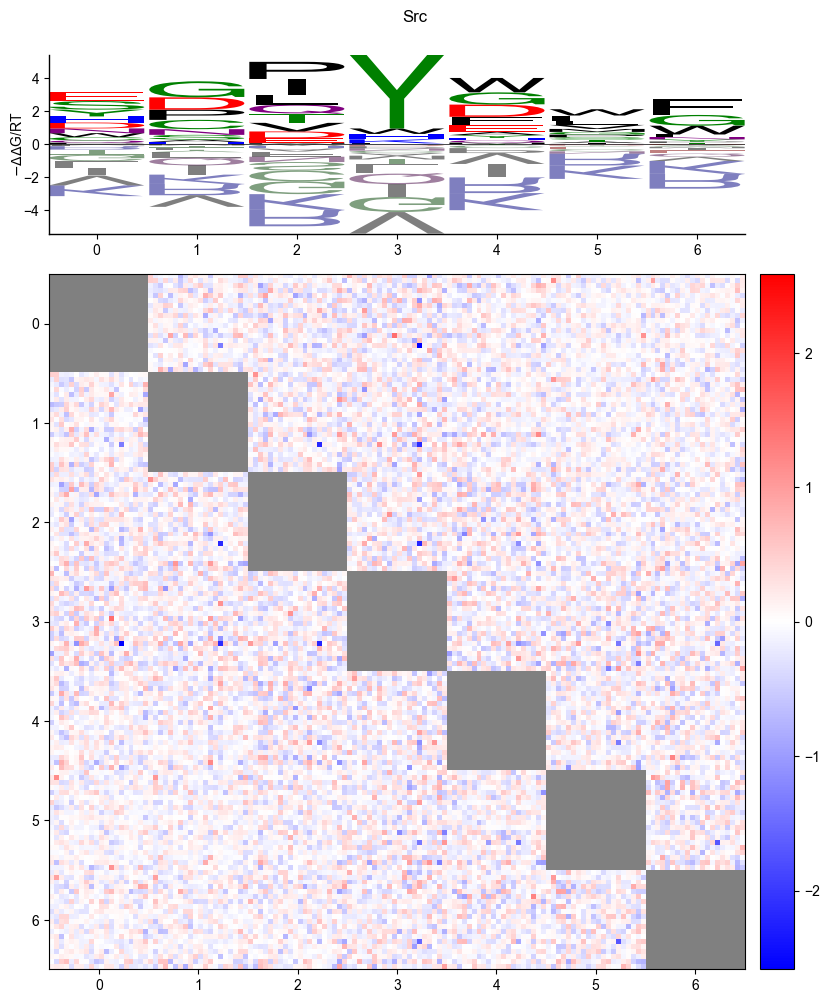
Logo
pyprobound.plotting.logo(psam)
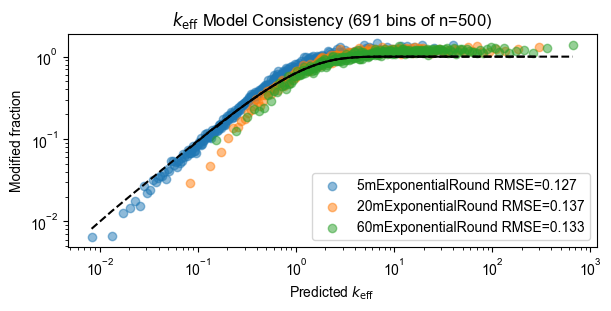
Model consistency
pyprobound.plotting.keff_consistency(experiment, train_count_table)
Validation
HPLC
validation_df = pyprobound.get_dataframe(["Src_HPLC.tsv"])
validation_ct = pyprobound.CountTable(validation_df, alphabet)
observed = validation_ct.target[:, 0]
with torch.inference_mode():
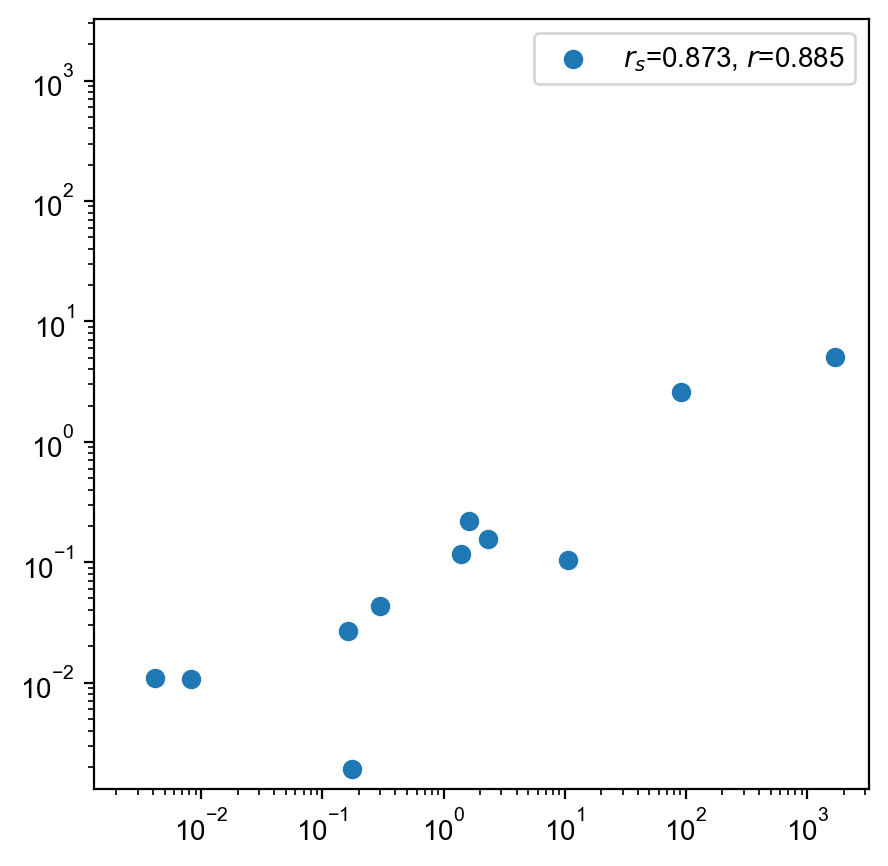
predicted = torch.exp(round_1.log_aggregate(validation_ct.seqs))
spearman_r = scipy.stats.spearmanr(observed.log(), predicted.log()).statistic
pearson_r = scipy.stats.pearsonr(observed.log(), predicted.log()).statistic
plt.figure(figsize=(5, 5))
plt.scatter(
predicted, observed, label=f"$r_s$={spearman_r:.3f}, $r$={pearson_r:.3f}"
)
plt.xscale("log")
plt.yscale("log")
plt.xlim(min(plt.xlim()[0], plt.ylim()[0]), max(plt.xlim()[1], plt.ylim()[1]))
plt.ylim(plt.xlim())
plt.legend()
plt.show()
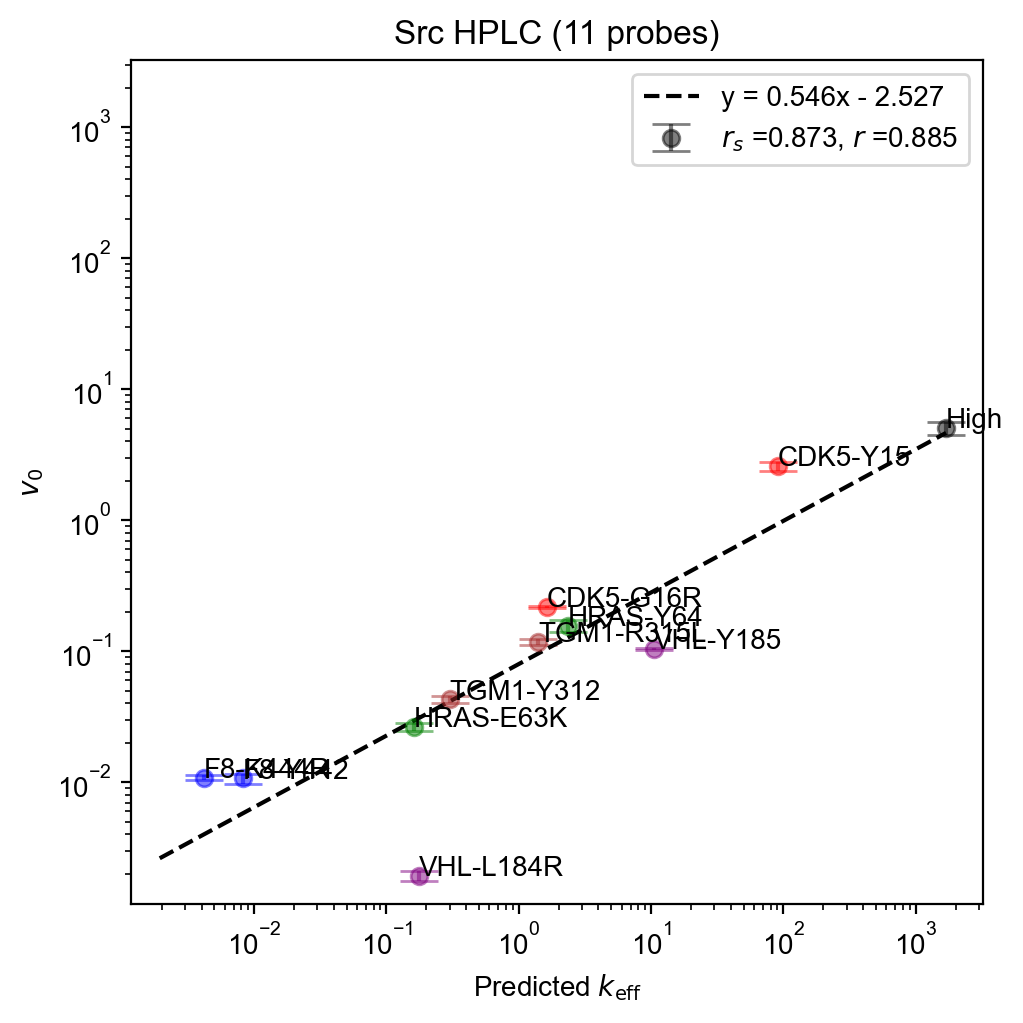
fit = pyprobound.fitting.LogFit(
round_1,
validation_ct,
prediction=lambda log_aggregate: log_aggregate,
device="cpu",
update_construct=True,
name="Src HPLC",
)
fit.plot(
xlabel=r"Predicted $k_{\mathrm{eff}}$",
ylabel=r"$v_0$",
labels=[
"High",
"F8-Y442",
"F8-K444R",
"TGM1-Y312",
"TGM1-R315L",
"VHL-Y185",
"VHL-L184R",
"HRAS-Y64",
"HRAS-E63K",
"CDK5-Y15",
"CDK5-G16R",
],
colors=(
["black"]
+ ["blue"] * 2
+ ["brown"] * 2
+ ["purple"] * 2
+ ["green"] * 2
+ ["red"] * 2
),
)