This example is taken from the ProBound web server.
This example produces a single CTCF binding model by training on data from two experiments, SMILE-seq and HT-SELEX, jointly.
import torch
import pyprobound
import pyprobound.plotting
Data specification
alphabet = pyprobound.alphabets.DNA()
url = "http://pbdemo.x3dna.org/files/example_data/multiTF/"
dataframe_SMiLE = pyprobound.get_dataframe(
f"{url}countTable.0.CTCF_r3.tsv.gz"
) # SMiLE-seq count table generated from Isakova et al. (2017)
dataframe_SELEX = pyprobound.get_dataframe(
f"{url}countTable.0.CTCF_ESAJ_TAGCGA20NGCT.tsv.gz"
) # SELEX count table generated from Jolma et al. (2013)
count_table_SMiLE = pyprobound.CountTable(
dataframe_SMiLE,
alphabet,
left_flank="ACACTCTTTCCCTACACGACGCTCTTCCGATCTTGACGTC",
right_flank="GACGTCAGATCGGAAGAGCTCGTATGCCGTCTTCTGCTTG",
left_flank_length=5,
right_flank_length=5,
)
count_table_SELEX = pyprobound.CountTable(
dataframe_SELEX,
alphabet,
left_flank="CGGAGTCGGCAAGCAGAAGACGGCATACGATAGC",
right_flank="TCGCTAGATCGGAAGAGCGTCG",
left_flank_length=5,
right_flank_length=5,
)
count_tables = [count_table_SMiLE, count_table_SELEX]
Model specification
PSAMs
nonspecific = pyprobound.layers.NonSpecific(alphabet=alphabet, name="NS")
psam_bias = pyprobound.layers.PSAM(
kernel_size=1, alphabet=alphabet, score_reverse=False
)
psam_1 = pyprobound.layers.PSAM(
kernel_size=12,
alphabet=alphabet,
max_kernel_size=18,
increment_flank=True,
shift_footprint_heuristic=True,
increment_footprint=True,
increment_flank_with_footprint=True,
)
psam_2 = pyprobound.layers.PSAM(
kernel_size=12,
alphabet=alphabet,
max_kernel_size=18,
increment_flank=True,
shift_footprint_heuristic=True,
increment_footprint=True,
increment_flank_with_footprint=True,
)
Modes
mode_nonspecific_SMiLE = pyprobound.Mode.from_nonspecific(
nonspecific, count_table_SMiLE
)
mode_bias_SMiLE = pyprobound.Mode.from_psam(
psam_bias, count_table_SMiLE, train_posbias=True
)
mode_1_SMiLE = pyprobound.Mode.from_psam(psam_1, count_table_SMiLE)
mode_2_SMiLE = pyprobound.Mode.from_psam(psam_2, count_table_SMiLE)
modes_SMiLE = [
mode_nonspecific_SMiLE,
mode_bias_SMiLE,
mode_1_SMiLE,
mode_2_SMiLE,
]
mode_nonspecific_SELEX = pyprobound.Mode.from_nonspecific(
nonspecific, count_table_SELEX
)
mode_bias_SELEX = pyprobound.Mode.from_psam(
psam_bias, count_table_SELEX, train_posbias=True
)
mode_1_SELEX = pyprobound.Mode.from_psam(psam_1, count_table_SELEX)
mode_2_SELEX = pyprobound.Mode.from_psam(psam_2, count_table_SELEX)
modes_SELEX = [
mode_nonspecific_SELEX,
mode_bias_SELEX,
mode_1_SELEX,
mode_2_SELEX,
]
Rounds
rounds_SMiLE = pyprobound.rounds.repeat_round(
modes_SMiLE, 2, pyprobound.rounds.BoundUnsaturatedRound
)
rounds_SELEX = pyprobound.rounds.repeat_round(
modes_SELEX, 5, pyprobound.rounds.BoundUnsaturatedRound
)
Experiments
experiment_SMiLE = pyprobound.Experiment(
rounds_SMiLE,
name="CTCF-SMiLE",
counts_per_round=count_table_SMiLE.counts_per_round,
)
experiment_SELEX = pyprobound.Experiment(
rounds_SELEX,
name="CTCF-SELEX",
counts_per_round=count_table_SELEX.counts_per_round,
)
experiments = [experiment_SMiLE, experiment_SELEX]
Model
model = pyprobound.MultiExperimentLoss(experiments, pseudocount=20)
Fitting
optimizer = pyprobound.Optimizer(
model,
count_tables,
greedy_threshold=2e-4,
device="cpu",
checkpoint="CTCF_multiexp.pt",
output="CTCF_multiexp.txt",
)
optimizer.train_sequential()
tensor(1.0221)
optimizer.reload()
{'time': 'Wed Apr 24 02:23:43 2024',
'version': '1.3.1',
'flank_lengths': ((13, 13), (13, 13))}
Loss
with torch.inference_mode():
loss, reg = model(count_tables)
print(loss, reg, loss + reg)
tensor(1.0040) tensor(0.0181) tensor(1.0221)
Logo
pyprobound.plotting.logo(psam_bias)
pyprobound.plotting.logo(psam_1)
pyprobound.plotting.logo(psam_1, reverse=True)
pyprobound.plotting.logo(psam_2)
pyprobound.plotting.logo(psam_2, reverse=True)
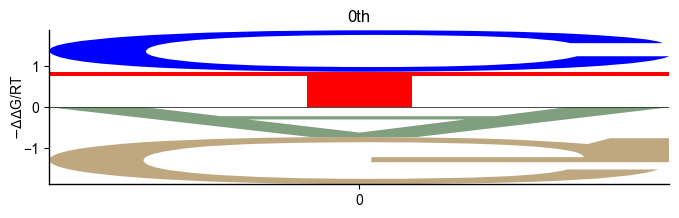
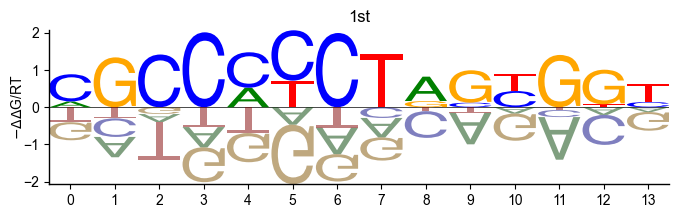
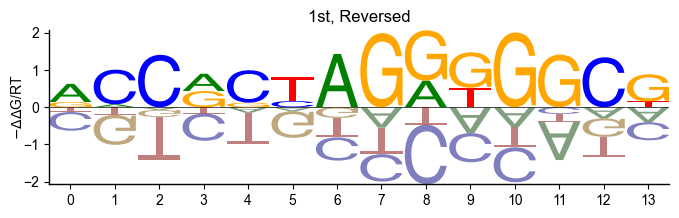
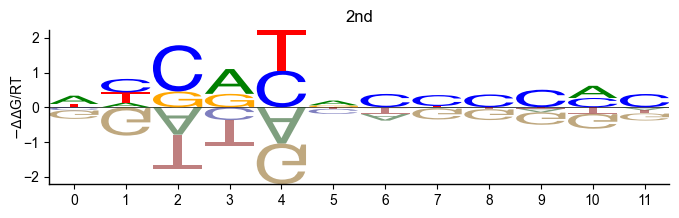
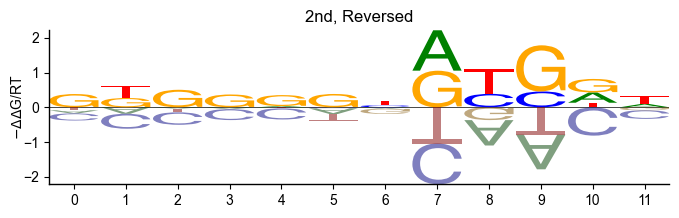
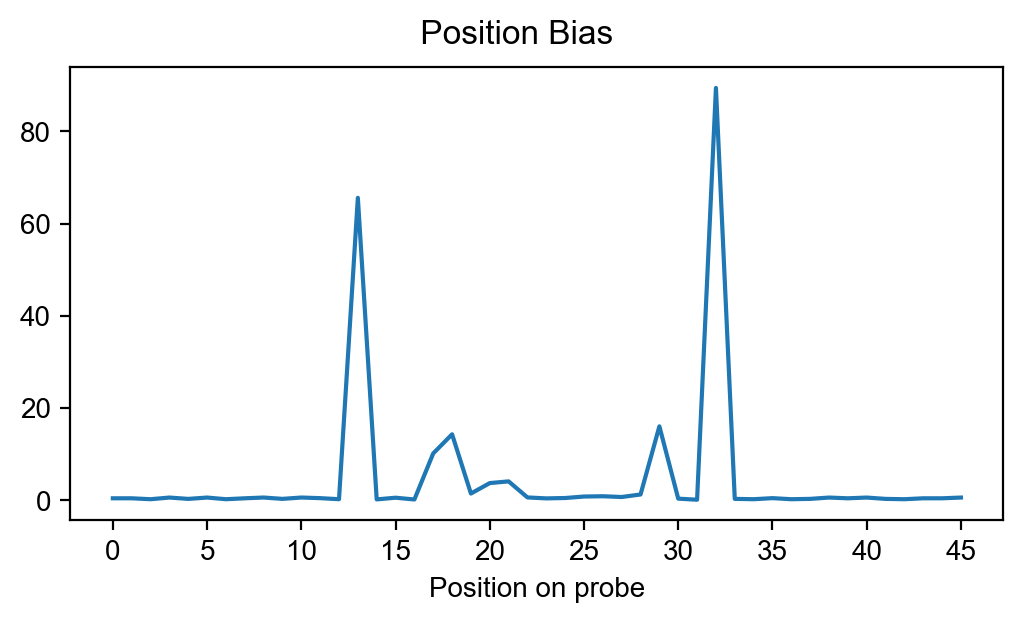
Position bias
pyprobound.plotting.posbias(mode_bias_SMiLE)
pyprobound.plotting.posbias(mode_bias_SELEX)
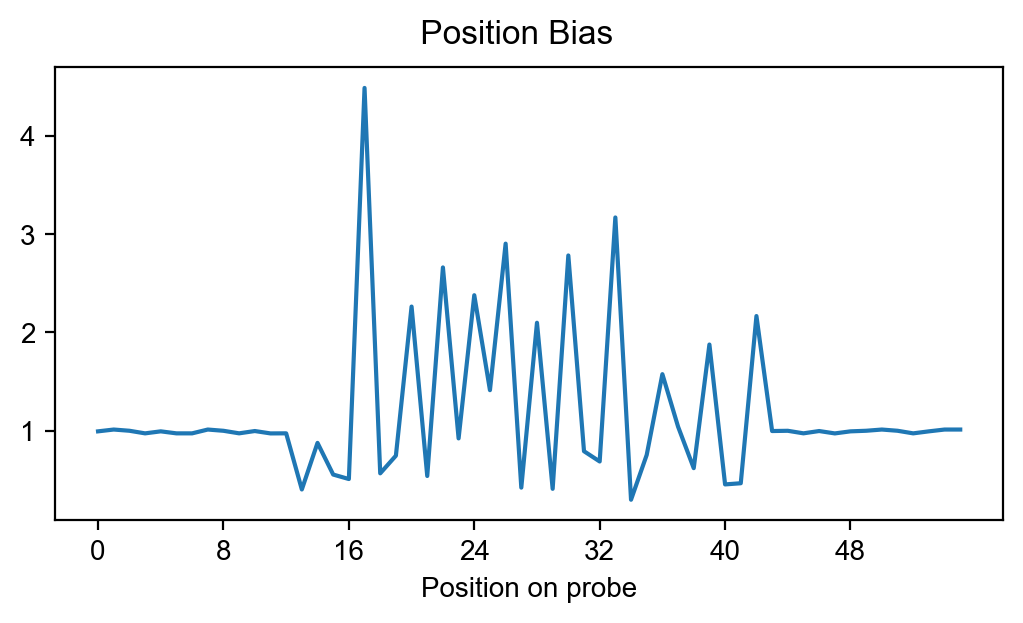
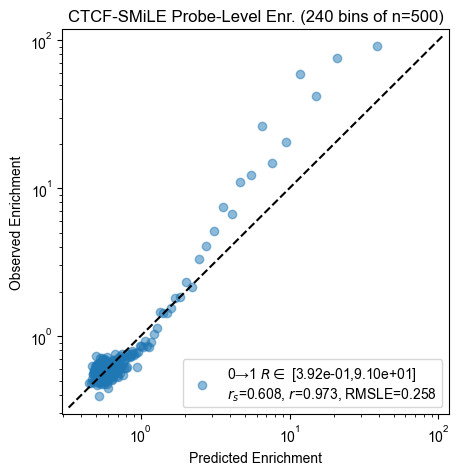
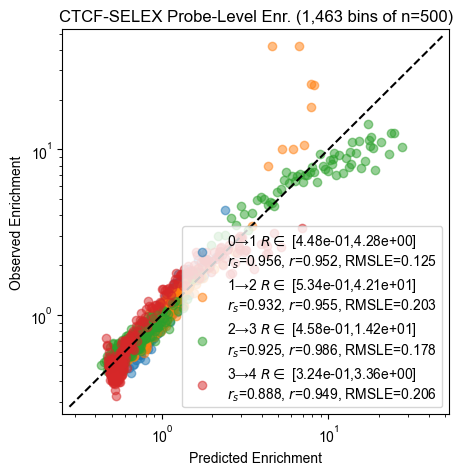
Probe enrichment
for experiment, count_table in zip(experiments, count_tables):
pyprobound.plotting.probe_enrichment(experiment, count_table)
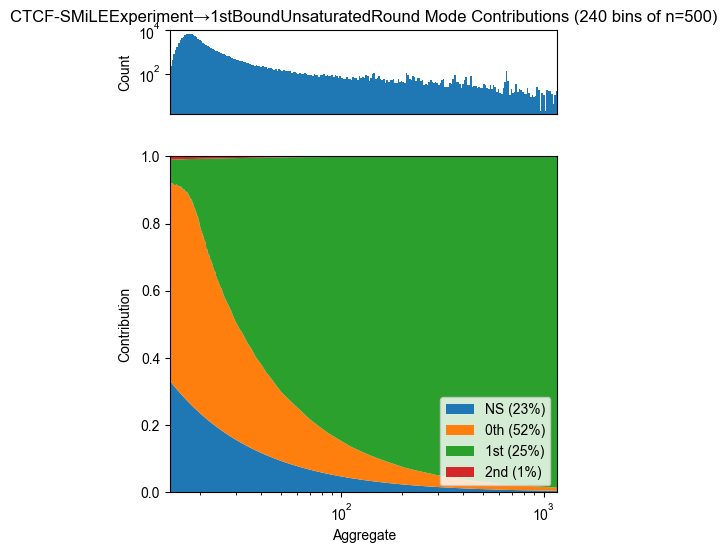
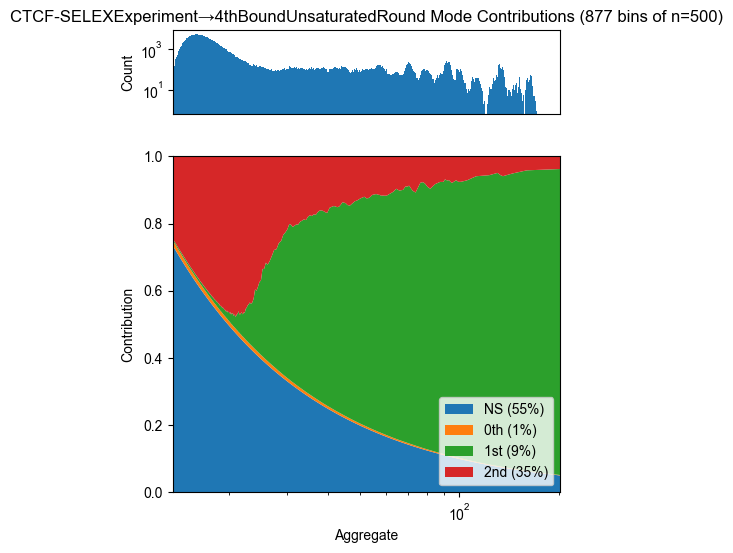
Mode contribution
for experiment, count_table in zip(experiments, count_tables):
pyprobound.plotting.contribution(experiment.rounds[-1], count_table)