PyProBound can be extended to work on protein binding microarray (PBM) data, akin to the FeatureREDUCE algorithm.
This example follows from the other CEBPγ example, but is trained on PBM data.
import pandas as pd
import torch
import torch.nn.functional as F
import pyprobound
import pyprobound.plotting
import pyprobound.fitting
Data specification
alphabet = pyprobound.alphabets.DNA()
dataframe = pd.read_csv(
(
"https://www.ncbi.nlm.nih.gov/geo/download/"
"?acc=GSM1291372&format=file&file=GSM1291372"
r"%5FpTH5257%5FHK%5F8mer%5F1305%2Eraw%2Etxt%2Egz"
),
header=0,
index_col=None,
sep="\t",
compression="gzip",
) # PBM table generated from Weirauch et al. (2014)
dataframe.index = dataframe["linker_sequence"] + dataframe["pbm_sequence"]
dataframe = dataframe.loc[dataframe["control"] == "FALSE"]
dataframe = (
dataframe["mean_signal_intensity"] - dataframe["mean_background_intensity"]
).to_frame()
dataframe.head()
| 0 | |
|---|---|
| CCTGTGTGAAATTGTTATCCGCTCTGCCAGTTTAGGTGGCGCCCGGAACCCTTAACCCAT | 2948.2663 |
| CCTGTGTGAAATTGTTATCCGCTCTCATGTAGAGCCCTAAAACTGGGACTAAGCCGACCT | 4445.8552 |
| CCTGTGTGAAATTGTTATCCGCTCTGGACGCAACATGCAGCTGCACAAGTCACTTGTGAG | 18942.4798 |
| CCTGTGTGAAATTGTTATCCGCTCTAAGATTGACACGAGACTATCCAGTATACCCCTTTC | 4117.4818 |
| CCTGTGTGAAATTGTTATCCGCTCTGTGCTCGAAGAAAGGGCCACCGCGTCCCTCGCTAG | 4073.3036 |
# Pad to account for overhang binding
intensity_table = pyprobound.CountTable(
dataframe, alphabet, right_flank="-" * 11, right_flank_length=11
)
Model specification
PSAMs
nonspecific = pyprobound.layers.NonSpecific(alphabet=alphabet, name="NS")
psam = pyprobound.layers.PSAM(
alphabet=alphabet,
kernel_size=12,
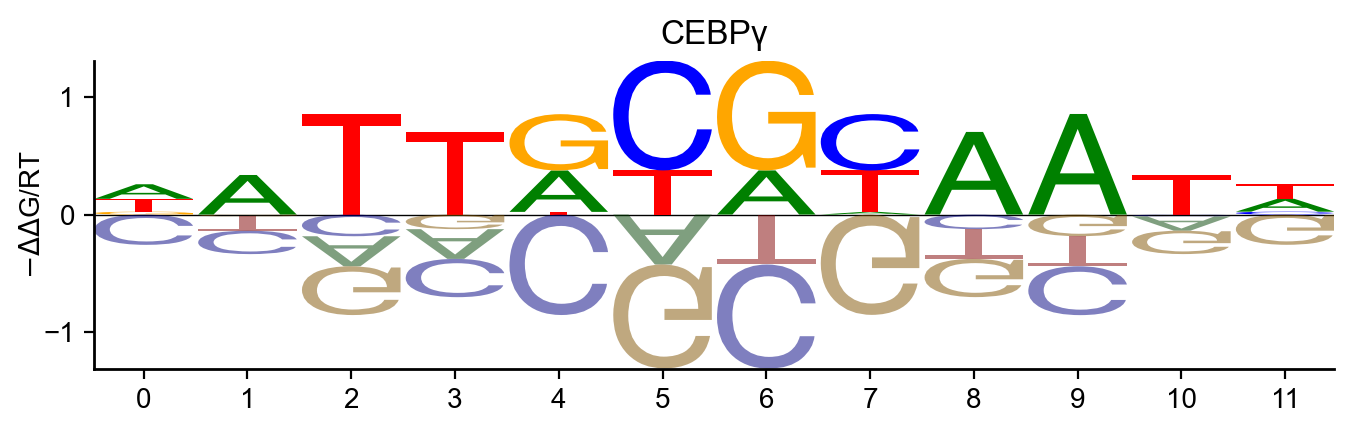
seed=["**TTGC------"],
seed_scale=6,
symmetry=[1, 2, 3, 4, 5, 6, -6, -5, -4, -3, -2, -1],
name="CEBPγ",
)
Modes
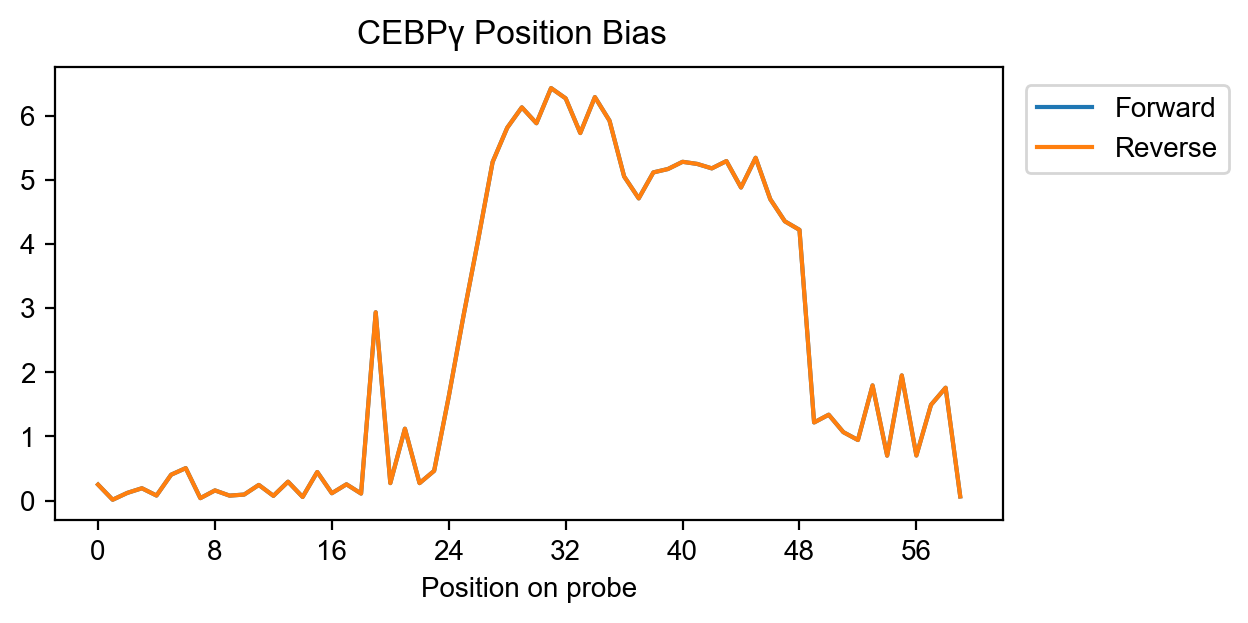
# Train position bias to account for bias in TF binding along a probe
modes = [
pyprobound.Mode.from_nonspecific(nonspecific, intensity_table),
pyprobound.Mode.from_psam(psam, intensity_table, train_posbias=True),
]
Rounds
# Here, we create a round with `None` as the reference round
# because there is no round-over-round enrichment
rnd = pyprobound.rounds.BoundRound.from_binding(modes, None)
# Note: if using BoundUnsaturatedRound, `train_depth` should be `False`
# since the depth parameter can be absorbed by activity parameters
Model
model = pyprobound.MultiRoundMSLELoss([rnd])
Fitting
optimizer = pyprobound.Optimizer(
model,
[intensity_table],
device="cpu",
checkpoint="CEBPg_PBM.pt",
output="CEBPg_PBM.txt",
)
optimizer.train_sequential()
tensor(0.2489)
optimizer.reload()
{'time': 'Wed Aug 7 09:00:16 2024',
'version': '1.4.0',
'flank_lengths': ((0, 11),)}
Loss
with torch.inference_mode():
loss, reg = model([intensity_table])
print(loss, reg, loss + reg)
tensor(0.2480) tensor(0.0009) tensor(0.2489)
Logo
pyprobound.plotting.logo(psam)
Position bias
pyprobound.plotting.posbias(modes[-1])
Plot
fit = pyprobound.fitting.LogFit(
rnd,
intensity_table,
prediction=F.logsigmoid, # Use `lambda x: x` if BoundUnsaturatedRound
device="cpu",
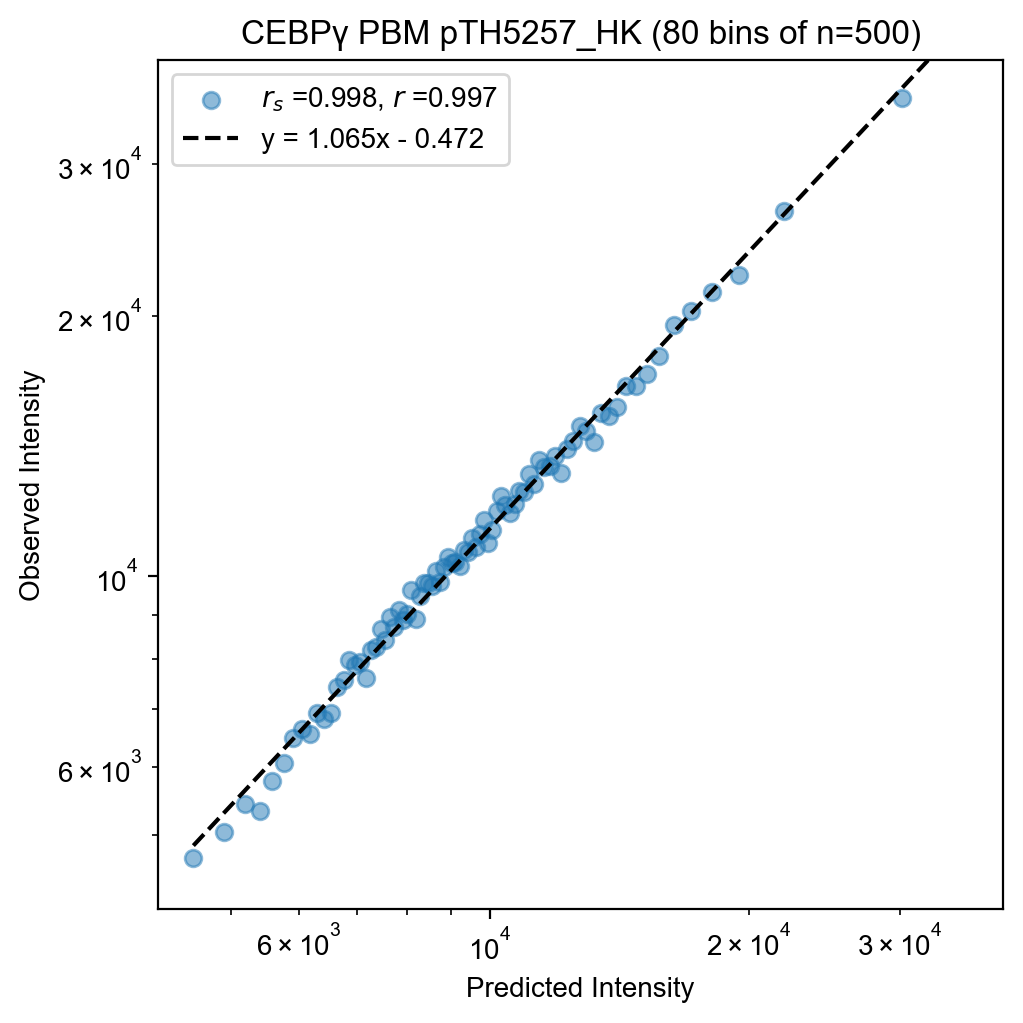
name="CEBPγ PBM pTH5257_HK",
)
# Skip the next line if BoundUnsaturatedRound
torch.nn.init.constant_(fit.scale, rnd.log_depth)
fit.plot(kernel=500, xlabel="Predicted Intensity", ylabel="Observed Intensity")