This example is taken from the ProBound web server, and corresponds to Figure 3e in the original Nature Biotech publication.
This example produces a single CEBPγ binding model that includes parameters for the base modifications meCpG, 5hmC, and 6mA. It does so by training on EpiSELEX-seq data containing libraries for each modification.
import pandas as pd
import torch
import torch.nn.functional as F
import pyprobound
import pyprobound.plotting
import pyprobound.fitting
Data specification
alphabet = pyprobound.alphabets.Alphabet(
alphabet=["A", "C", "a", "c", "d", "h", "g", "t", "G", "T"],
complement=True,
color_scheme={
"A": [0.0, 0.5, 0.0],
"C": [0.0, 0.0, 1.0],
"G": [1.0, 0.65, 0.0],
"T": [1.0, 0.0, 0.0],
"DH": "black",
},
)
url = "http://pbdemo.x3dna.org/files/example_data/multiEpiSELEX/"
dataframe_None = pyprobound.get_dataframe(
f"{url}countTable.0.run_06_05_17__R1_CEBPg_homo_75nM_lowBand__None.tsv.gz"
)
dataframe_5mCG = pyprobound.get_dataframe(
f"{url}countTable.1.run_06_05_17__R1_CEBPg_homo_75nM_lowBand__5mCG.tsv.gz"
)
dataframe_5hmC = pyprobound.get_dataframe(
f"{url}countTable.2.run_06_05_17__R1_CEBPg_homo_75nM_lowBand__5hmC.tsv.gz"
)
dataframe_6mA = pyprobound.get_dataframe(
f"{url}countTable.3.run_06_05_17__R1_CEBPg_homo_75nM_lowBand__6mA.tsv.gz"
)
count_table_None = pyprobound.CountTable(
dataframe_None,
alphabet,
left_flank="GGTAGTGGAGGTGGGCCTGG",
right_flank="CCAGGGAGGTGGAGTAGG",
left_flank_length=3,
right_flank_length=3,
)
count_table_5mCG = pyprobound.CountTable(
dataframe_5mCG,
alphabet,
left_flank="GGTAGTGGAGGGCACCCTGG",
right_flank="CCAGGGAGGTGGAGTAGG",
left_flank_length=3,
right_flank_length=3,
transliterate={"CG": "dh"},
)
count_table_5hmC = pyprobound.CountTable(
dataframe_5hmC,
alphabet,
left_flank="GGTAGTGGAGGCAGTCCTGG",
right_flank="CCAGGGAGGTGGAGTAGG",
left_flank_length=3,
right_flank_length=3,
transliterate={"C": "c"},
)
count_table_6mA = pyprobound.CountTable(
dataframe_6mA,
alphabet,
left_flank="GGTAGTGGAGGAGTGCCTGG",
right_flank="CCAGGGAGGTGGAGTAGG",
left_flank_length=3,
right_flank_length=3,
transliterate={"A": "a"},
)
count_tables = [
count_table_None,
count_table_5mCG,
count_table_5hmC,
count_table_6mA,
]
Model specification
PSAMs
nonspecific = pyprobound.layers.NonSpecific(alphabet=alphabet, name="NS")
psam = pyprobound.layers.PSAM(
alphabet=alphabet,
kernel_size=12,
pairwise_distance=1,
seed=["**TTGC------"],
seed_scale=6,
symmetry=[1, 2, 3, 4, 5, 6, -6, -5, -4, -3, -2, -1],
increment_flank=True,
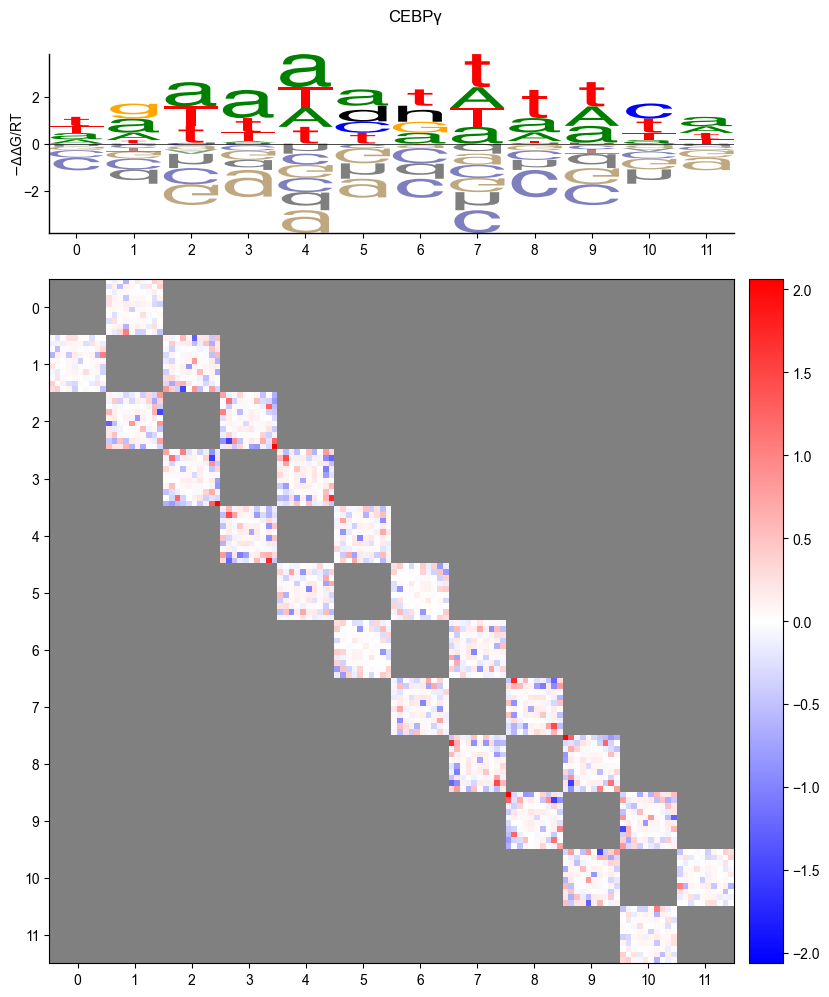
name="CEBPγ",
)
Modes
modes_None = [
pyprobound.Mode.from_nonspecific(nonspecific, count_table_None),
pyprobound.Mode.from_psam(psam, count_table_None),
]
modes_5mCG = [
pyprobound.Mode.from_nonspecific(nonspecific, count_table_5mCG),
pyprobound.Mode.from_psam(psam, count_table_5mCG),
]
modes_5hmC = [
pyprobound.Mode.from_nonspecific(nonspecific, count_table_5hmC),
pyprobound.Mode.from_psam(psam, count_table_5hmC),
]
modes_6mA = [
pyprobound.Mode.from_nonspecific(nonspecific, count_table_6mA),
pyprobound.Mode.from_psam(psam, count_table_6mA),
]
Rounds
round_0_None = pyprobound.rounds.InitialRound()
round_1_None = pyprobound.rounds.BoundUnsaturatedRound.from_binding(
modes_None, round_0_None
)
round_0_5mCG = pyprobound.rounds.InitialRound()
round_1_5mCG = pyprobound.rounds.BoundUnsaturatedRound.from_binding(
modes_5mCG, round_0_5mCG
)
round_0_5hmC = pyprobound.rounds.InitialRound()
round_1_5hmC = pyprobound.rounds.BoundUnsaturatedRound.from_binding(
modes_5hmC, round_0_5hmC
)
round_0_6mA = pyprobound.rounds.InitialRound()
round_1_6mA = pyprobound.rounds.BoundUnsaturatedRound.from_binding(
modes_6mA, round_0_6mA
)
Experiments
experiment_None = pyprobound.Experiment(
[round_0_None, round_1_None], name="None"
)
experiment_5mCG = pyprobound.Experiment(
[round_0_5mCG, round_1_5mCG], name="5mCG"
)
experiment_5hmC = pyprobound.Experiment(
[round_0_5hmC, round_1_5hmC], name="5hmC"
)
experiment_6mA = pyprobound.Experiment([round_0_6mA, round_1_6mA], name="6mA")
experiments = [
experiment_None,
experiment_5mCG,
experiment_5hmC,
experiment_6mA,
]
Model
model = pyprobound.MultiExperimentLoss(experiments, pseudocount=0)
Fitting
optimizer = pyprobound.Optimizer(
model,
count_tables,
greedy_threshold=2e-4,
device="cpu",
checkpoint="CEBPg.pt",
output="CEBPg.txt",
)
optimizer.train_sequential()
tensor(0.6521)
optimizer.reload()
{'time': 'Wed Apr 24 01:25:32 2024',
'version': '1.3.1',
'flank_lengths': ((3, 3), (3, 3), (3, 3), (3, 3))}
Loss
with torch.inference_mode():
loss, reg = model(count_tables)
print(loss, reg, loss + reg)
tensor(0.6519) tensor(0.0001) tensor(0.6521)
Logo
pyprobound.plotting.logo(psam)
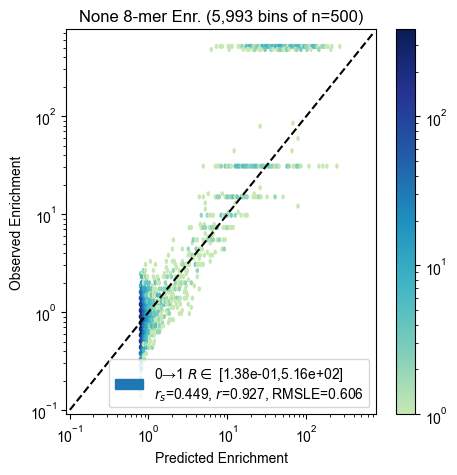
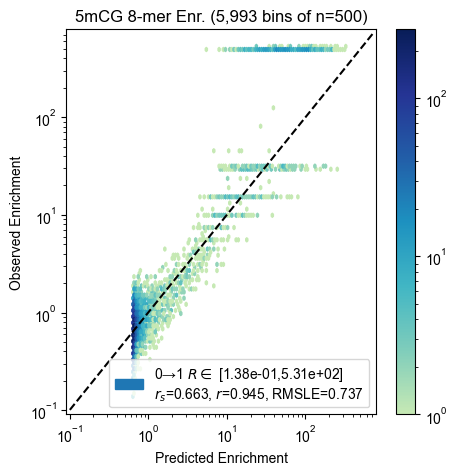
8-mer enrichment
for experiment, count_table in zip(experiments, count_tables):
pyprobound.plotting.kmer_enrichment(experiment, count_table, kmer_length=8)
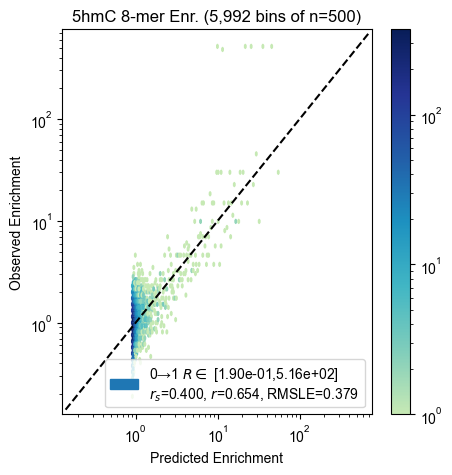
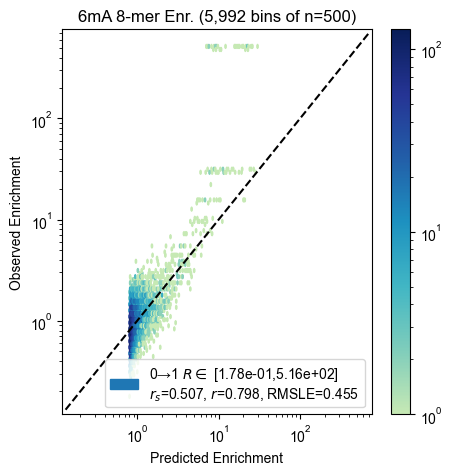
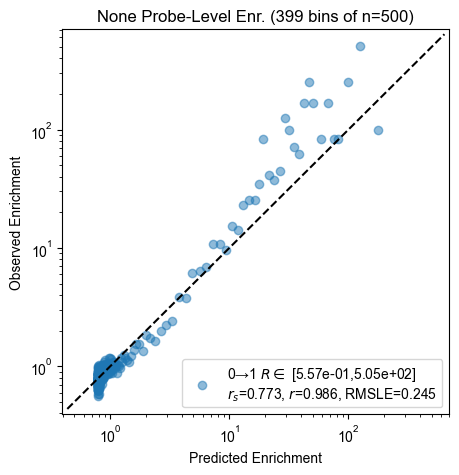
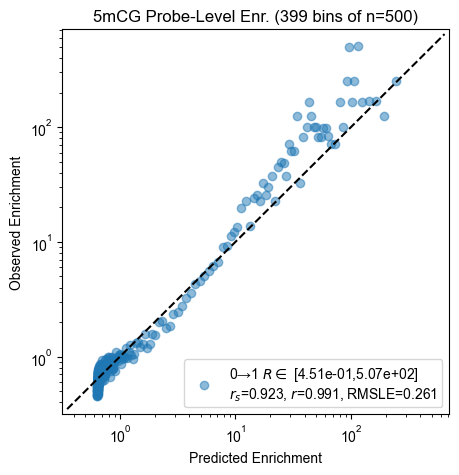
Probe enrichment
for experiment, count_table in zip(experiments, count_tables):
pyprobound.plotting.probe_enrichment(experiment, count_table)
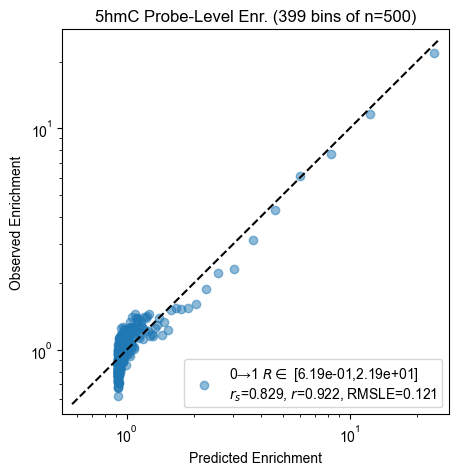
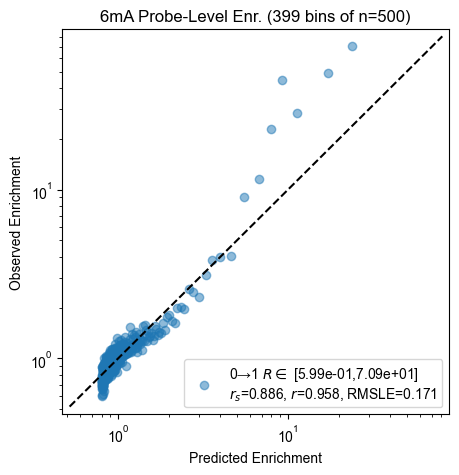
Validation
PBM
# PBM table generated from Weirauch et al. (2014)
pTH5257_HK_df = pd.read_csv(
(
"https://www.ncbi.nlm.nih.gov/geo/download/"
"?acc=GSM1291372&format=file&file=GSM1291372"
r"%5FpTH5257%5FHK%5F8mer%5F1305%2Eraw%2Etxt%2Egz"
),
header=0,
index_col=None,
sep="\t",
compression="gzip",
)
pTH5257_HK_df.index = (
pTH5257_HK_df["linker_sequence"] + pTH5257_HK_df["pbm_sequence"]
)
pTH5257_HK_df = pTH5257_HK_df.loc[pTH5257_HK_df["control"] == "FALSE"]
pTH5257_HK_df = (
pTH5257_HK_df["mean_signal_intensity"]
- pTH5257_HK_df["mean_background_intensity"]
).to_frame()
pTH5257_HK_ct = pyprobound.CountTable(
pTH5257_HK_df, alphabet, right_flank="-" * 11, right_flank_length=11
)
pTH5257_HK_df.head()
| 0 | |
|---|---|
| CCTGTGTGAAATTGTTATCCGCTCTGCCAGTTTAGGTGGCGCCCGGAACCCTTAACCCAT | 2948.2663 |
| CCTGTGTGAAATTGTTATCCGCTCTCATGTAGAGCCCTAAAACTGGGACTAAGCCGACCT | 4445.8552 |
| CCTGTGTGAAATTGTTATCCGCTCTGGACGCAACATGCAGCTGCACAAGTCACTTGTGAG | 18942.4798 |
| CCTGTGTGAAATTGTTATCCGCTCTAAGATTGACACGAGACTATCCAGTATACCCCTTTC | 4117.4818 |
| CCTGTGTGAAATTGTTATCCGCTCTGTGCTCGAAGAAAGGGCCACCGCGTCCCTCGCTAG | 4073.3036 |
fit = pyprobound.fitting.LogFit(
round_1_None,
pTH5257_HK_ct,
prediction=F.logsigmoid,
update_construct=True,
train_offset=True,
train_hill=True,
device="cpu",
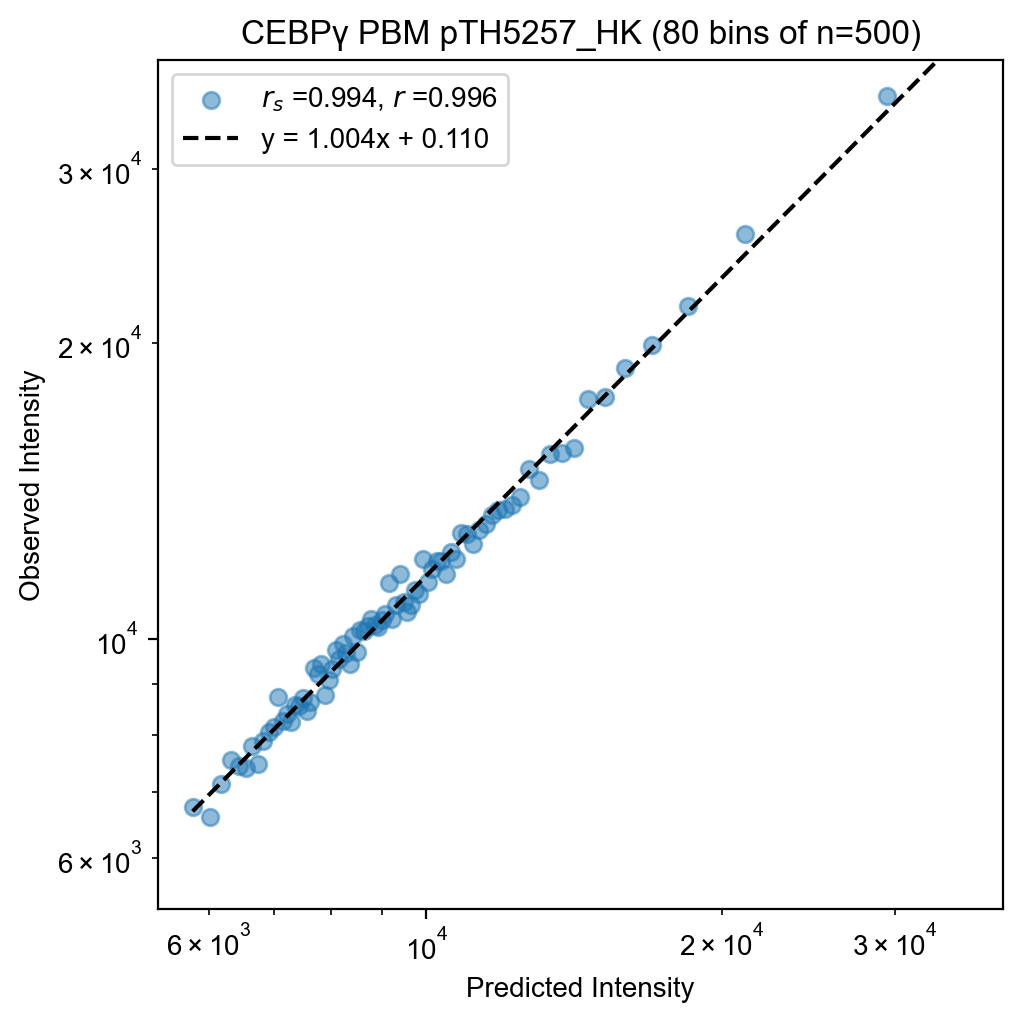
name="CEBPγ PBM pTH5257_HK",
checkpoint="CEBPg_pTH5257_HK.pt",
)
fit.fit()
fit.plot(kernel=500, xlabel="Predicted Intensity", ylabel="Observed Intensity")